Summary:
When Dopamine 2.0 released, it caused a large spike in traffic. We tried scaling to accommodate the sudden load on our servers, but MongoDB Atlas dropped the ball and failed to migrate our data over, which left us with 8 hours of downtime. We will be creating regular offsite backups and preemptively scaling for future jailbreaks.
What Happened:
At around 8:30 AM PST, Dopamine 2.0 was released. Like all jailbreak releases before it, a flood of customers eagerly came to our repo by either our website or through a package manager such as Sileo and Zebra.
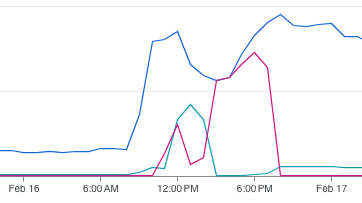
Normally, our web servers automatically scale to handle load, but this jailbreak release was quite a bit larger than previous ones. Initially, traffic was being handled just fine, but users kept coming in and at around 9:40 AM PST our servers capped out at the maximum that we set. At this point, our users were starting to notice and make comments.

We began to scale our servers shortly after, but at around 11:00 AM PST, our database had hit it’s connection limit and new connections were being refused.
For context: Havoc utilizes MongoDB Atlas for its database services. Admittedly, up until this point, we were on a shared VM and in order to handle more connections we would need to upgrade to a dedicated VM and migrate the data over. It’s hard to say that we procrastinated doing this earlier, considering the shared instance was more than sufficient in handling a typical day’s load.
The vast majority of database operations on Havoc are reads, not writes, which means we are able to heavily cache the bulk of the database’s load with Cloudflare. Nonetheless, shortly after hitting the limit, we realized what was going on and that we would have to scale the database.
The Atlas dashboard warns you this will cause “7-10 minutes” of downtime, which isn’t great but we weren’t left with much choice considering the site’s performance was not acceptable in its current form. So we bit the bullet at around 11:15 AM PST and waited…. The Atlas dashboard doesn’t give you much info on the status of a cluster upgrade, only a vague message about it taking “a few minutes” and a short banner at the top of the page indicating that data was being migrated.
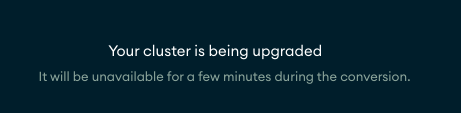
At this point, we were sitting ducks waiting for the upgrade to complete. The upgrade was taking way longer than it should have, so at around 11:45 AM PST, we reached out to MongoDB Atlas support to inquire about what was going on.
The support agent was very dismissive with our concerns, saying this was “expected downtime.” We continued to wait. After an hour of waiting and going back and forth with support, we expressed our frustration because the dashboard does not indicate anywhere that it will take an hour, instead it says statuses such as “a few minutes.” Not wanting to deal with the process of restoring from a backup with potential data loss/desync (because Atlas doesn’t let you create on demand backups on shared tier), we decided to wait it out.
At around 1:17 PM PST, the “migrating data” banner is gone from the top of the dashboard, but we now have a new message. “Your cluster upgrade failed during data migration, but a complete backup of your data is safely stored. Please contact our support staff for next steps.”
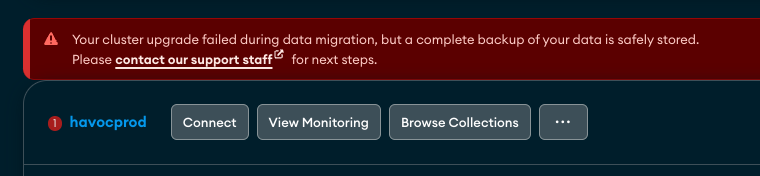
At this point, we realized we were in trouble. The obvious decision here was to restore from a backup and get the platform back up and running so we could provide some service and get checkout running again. We went to download a recent backup and we were greeted with a message stating “no snapshots available.”
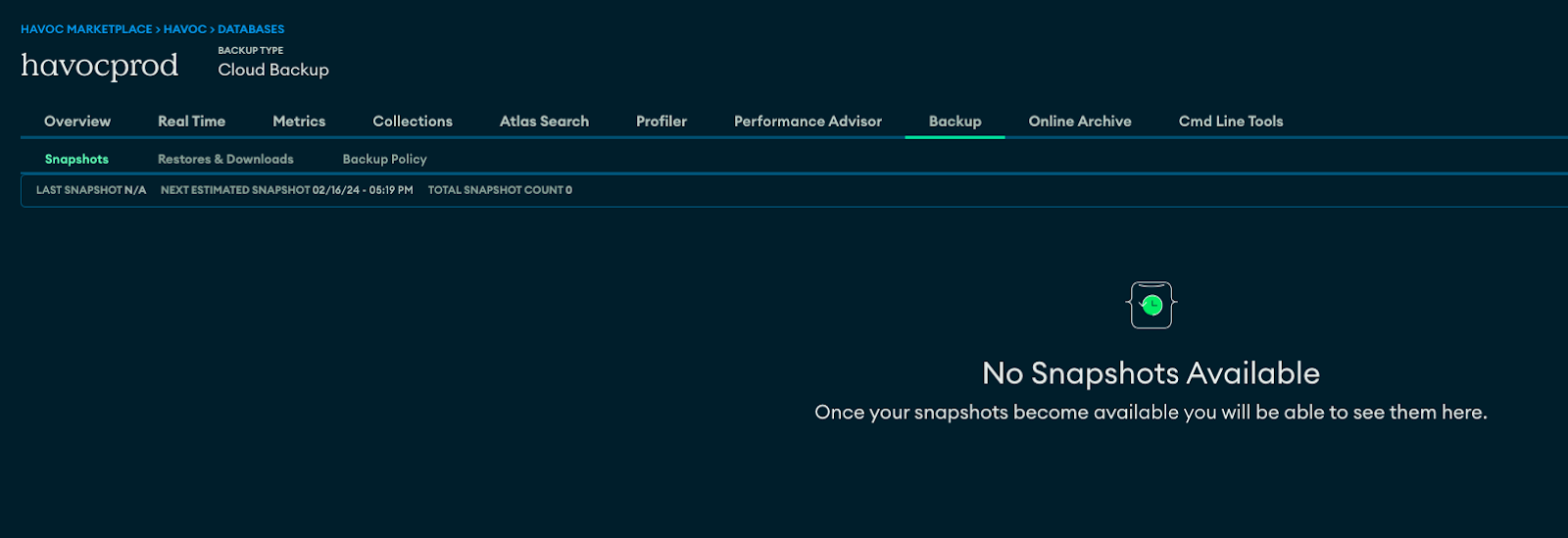
There were no backups. Why? We assume it’s because the data was associated with the previous cluster and this was part of the data migration. We then asked Atlas support but they never answered this specific question.
We sent Atlas support a message asking them about the data migration and our backups. After 30 minutes of silence on their end, we receive this response:
After having our internal support engineers take a closer look they have required your permission to perform the restore of the data. Keep in mind this does require you to stop all writes to your cluster, and this restore procedure will drop all of the data in the namespaces that exist in the archive that was created when the upgrade was initially tried and failed. Can I have you confirm the above in order to begin the remediation process? Thank you in advance.
Due to how critical this issue was and wanting to prepare ourselves for the possibility of data loss, we asked for clarification because the way the message was worded was confusing. We didn’t want to agree to something we didn’t fully understand, especially in this case when we’re talking about production data. At this point the platform was in a state where the database cluster was actually up and running but because the data migration failed, most, but not all records were missing. At this point, customers were being served an empty home page with no products to download (this is what the spike in 4xx requests above is).
It took Atlas support 56 minutes to respond to our inquiry for clarification. We sent many messages in between and even created several additional tickets in the hope that somebody would respond. We honestly thought the support agent went home for the night, considering they stopped responding right before 5PM EST and the chat status said they were inactive. It was only at this point did the support agent decide to let us know that chat support isn’t covered by the SLA and that we would need to purchase a support plan for guaranteed response times.
Keep in mind, the platform has been offline for almost 4 hours at this point. Wanting to be resolve this issue as quickly as possible, we signed up for a support plan (thankfully there was a 30 day free trial). We created a support case on MongoDB’s off-site support portal (you have to wait for them to sync their support database so you can actually log in) and wait.
About 40 minutes after creating a support case we got a response:
I know that another support agent is also in communication with you via the Support Chat service, however just for the record I'm also letting you know that our backend team is proceeding with the remediation since getting your nod to go ahead.
As I'd never seen this problem before in my 2.5 years working in and around Atlas I did a quick search to see how many instances we've ever seen of this particular problem. I'm relaying this information to you only because I was surprised to see that you were the only customer to ever report it. In addition, there have been a handful of internal-only reports of this by the test, dev and QA teams (like 6), but those were mostly in singular scenarios. I know it doesn't bring any comfort to know this, but I did want to provide you with this data to say that this really is an extremely unique occurrence and not something that I or anyone else here had seen recently. Thus you can feel some measure of confidence that if you underwent the same scenario with another shared-tier cluster, that the odds of it recurring would be very low.
Either another support agent or I will be updating you on progress of the remediation as things recover, however I assume you'll be keeping a close on it as well. If you have any questions or comments, feel free to update either the chat or case and we'll prioritize a response.
What the support agent was saying is that we just got unlucky, being the only people to report this issue in production. To be honest, after discussing it amongst our team and with others, we don’t believe this. Regardless, it was nice to know that this wasn’t our fault but the situation overall still sucked. We were extremely stressed out at this point and just wanted it to be over with. Eventually, the data was restored and thankfully there was no data loss.
However, although the data was restored, the performance was very poor. Our logs were still being flooded with 500s and the database was not keeping up despite the fact that this should’ve been a sufficient upgrade. It was quite difficult to even debug the issue due to connections taking a long time to establish and many performance resources on the Atlas dashboard were not working.

We reached out to support again and were told:
Your application is submitting a large workload on the cluster, which is causing the cluster to have frequent elections and restarts. The CPU load is very heavy on nodes whichever node is primary at the time. The primary node is frequently running out of read tickets as well.
One might think that we simply needed to scale up the database, again, however we were too afraid to click that button again and we had a pretty good feeling there was something else going on.
At this point users were hammering the servers, constantly hitting the refresh button, and greatly exacerbating the issue. But we knew based off of the web traffic that this should’ve been sufficient.
Admittedly, it took us quite a bit to figure out what the problem was, because our server alerts were throwing all kinds of bizarre mongo errors that we had never seen before. This all turned out to be a misdirection and the actual problem was that many of the queries being performed were not utilizing any kind of index. For some reason, the indexes from the previous cluster never got moved over and the server was thrown millions of records with nothing indexed. This was causing simple operations like a user navigating to their orders page to scan through tens of thousands of records and hang the CPU. Even after realizing this, it was a struggle just to get the database to manually create new indexes, oftentimes failing. This was however still faster than pulling the plug on however many web servers we had running at the time.
After all that, we managed to bring all our services back up after 8 painful and embarrassing hours.
Going Forward:
We have a handful of things that should prevent this from happening again:
- We will be creating off-site database backups regularly, so that even if MongoDB Atlas sinks again, we will have the option of immediately deploying a backup. This will allow the service to remain available even if it means some data is temporarily unavailable. We already keep redundant/off-site backups of seller assets so those should not be affected in any way.
- Having a dedicated database server allows us to scale much faster with little to no downtime, which would have avoided this issue altogether, since the point of failure was migrating the data from the shared to dedicated VM.
- We will scale all our services preemptively for new jailbreak releases, assuming we are given a heads up (which we have had thankfully for the last few).
- We now know to go right for the paid support on MongoDB Atlas when issues arise, because the chat support is useless.
We would like to thank our sellers and customers for being so understanding of our situation during this time. You guys are what gives the platform meaning in the first place and we’re sorry this ever happened.
The Havoc team can be reached for questions and info at:
![]() @HavocRepo
@HavocRepo
![]() havoc.app/discord
havoc.app/discord
![]() [email protected]
[email protected]